A Pony On The Move: How Migrations Work In Django 🐎
Django’s migration framework has been around since version 1.7 in 2014. From the outset, it had a long journey ahead, considering all the learnings and experience Andrew Godwin had with the 3rd party package South. However, Django’s migrations are not to be considered a rewrite of South as they work fundamentally different.
This talk will give an insight view into the components that make up Django’s migration framework. The talk will lay-out how these components fit and work together. It will outline major challenges and problems that were encountered and overcome along the way.
One of the goals of this talk is to reduce the entry barrier for potential Django contributors to the rather complex migration framework. There are some parts that are tricky and non-trivial and non-obvious. Thus, this talk is absolutely aimed at prospective contributors, regardless if they are first-time Django contributors or ones with a year-long track record.
Introduction
These 17 blocks are the main parts that make Django’s migration framework. And I want to try to bring some order to them. You might notice that I didn’t include the management commands. Nor did I include the individual database operations. The management commands use some of these components, but they are not particularly complex, compared to the rest. The individual migration operations are grouped together as “Operations” in the second row to the right.
I think the best way to structure this pile of boxes is to not sort them alphabetically as it is done here.
Instead I am going to arrange them with some arrows, showing which component is using which other component. That means, “A uses B” will be shown by an arrow pointing from A to B.
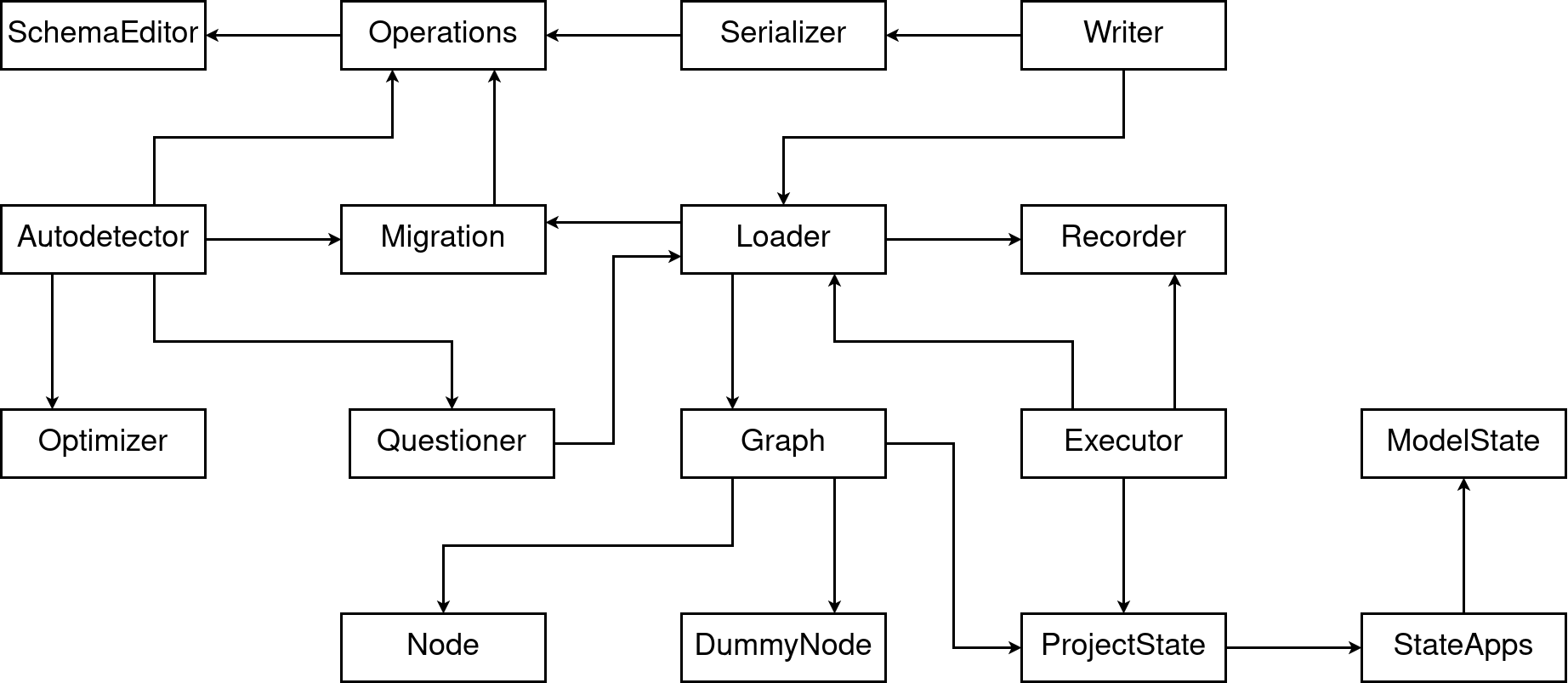
As you might notice, and also might have expected, there is a lot going on here. And I do mean A LOT! I’ve also omitted some arrows to keep it readable.
This talk will only cover the core parts of the migration system; other parts are ignored. But just because they aren’t covered here it doesn’t mean they’re not important. Each of these boxes is fundamental to the overall working of the migration framework.
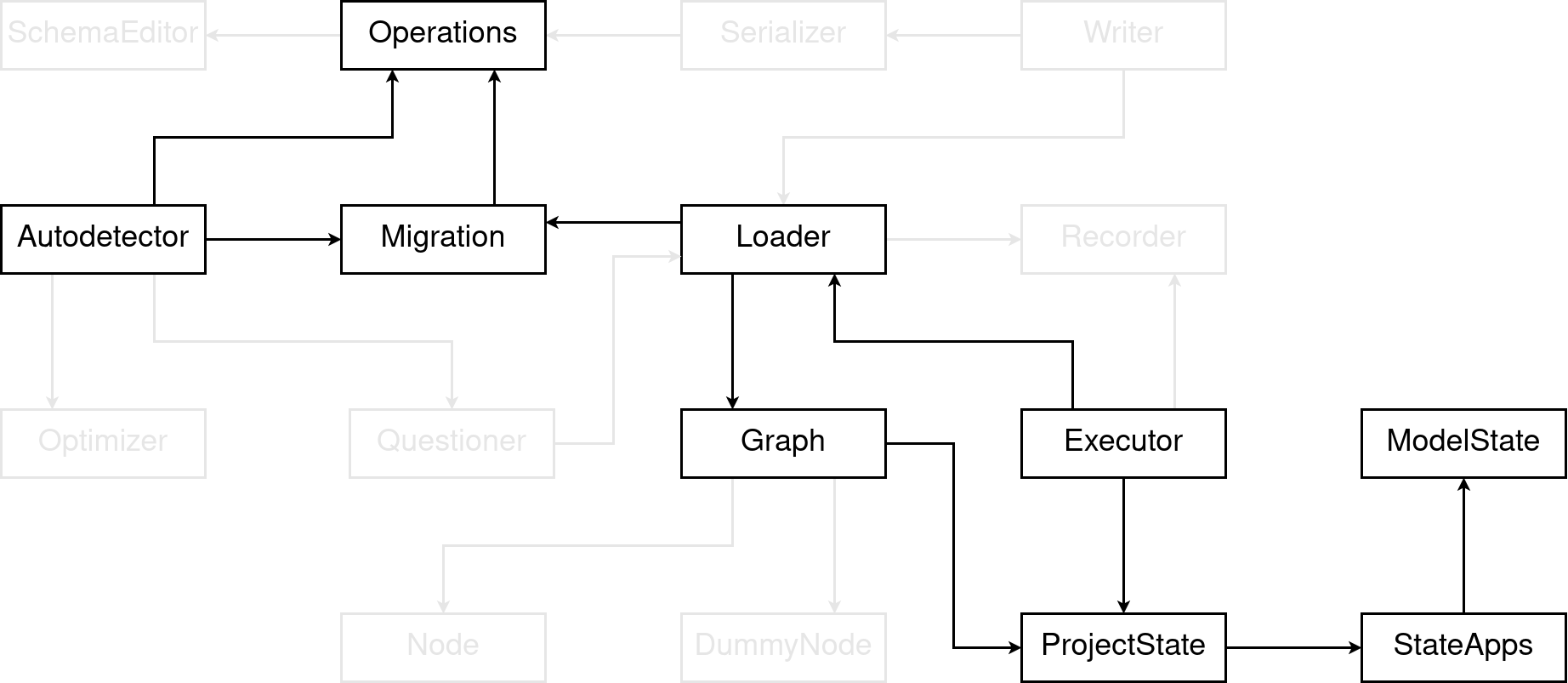
So, here’s what this post is going to cover. It’ll be about the core of the migration framework, the applying and un-applying of migrations and how Django figures out what you changed in your models to then create new migration files.
I will highlight the boxes as they’re being covered, and gray out all others that weren’t covered yet. Essentially, we’re going to be the pony that’s migrating through this graph of boxes.
ModelStates, ProjectStates, StateApps
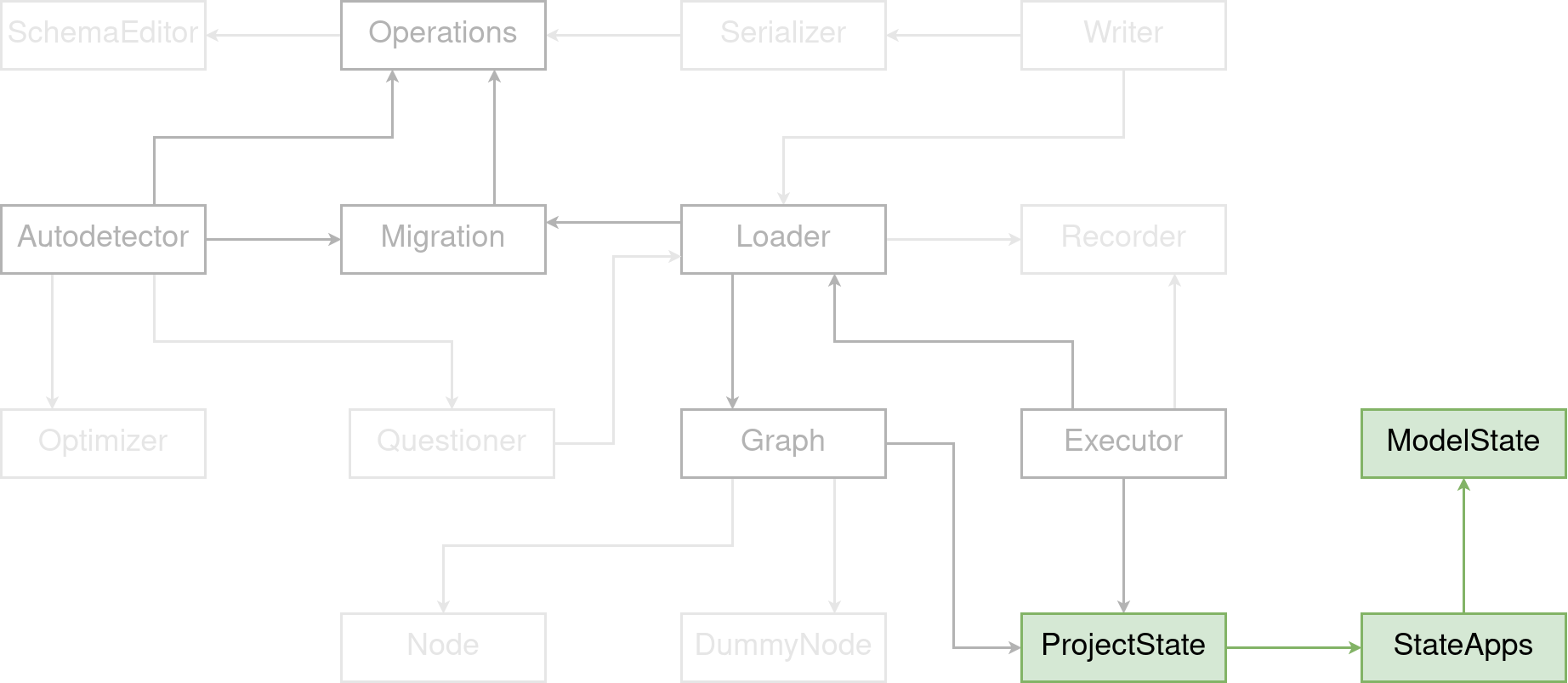
I want to start with these three pieces: ModelStates, ProjectStates, and StateApps. If you want to define a hierarchy of importance among all components making Django’s migration framework, these three are by far the most important ones. Nothing else works without them.
When we talk about migrations, we’re almost always talking about a timeline of your project. And we look at the state of the database and the corresponding models at some point in the life of your project. A ProjectState is essentially a snapshot at an arbitrary point in time on the timeline.
A ModelState represents a single model at some point on the timeline. In many ways, it looks like a Django model. But it isn’t. It’s a lightweight class without a lot of magic or logic. Because this class is instantiated hundreds, often thousands, and sometimes even millions of times. It contains a model’s name and app label. It’s fields, indexes, and constraints. And stuff like that.
The StateApps are pretty much an App registry as you may know from django.apps.registry.Apps. The place where all models of your Django project are registered. Its purpose inside the migration framework becomes more clear when we look at the Migration Executor later on. For now, let’s say, it’s an App registry with some models at some point in time, much like the ProjectState.
I just said, a ProjectState is a snapshot of models at some “point in time”. What that means is, whenever you or Django changes something in the models, such as deleting a field or adding a model, that is a new state of your project. Because your models before and after these events are different.
In Django’s migration system terminology, these “events” are called migration operations. And that’s what we’re looking at next.
Migrations and Operations
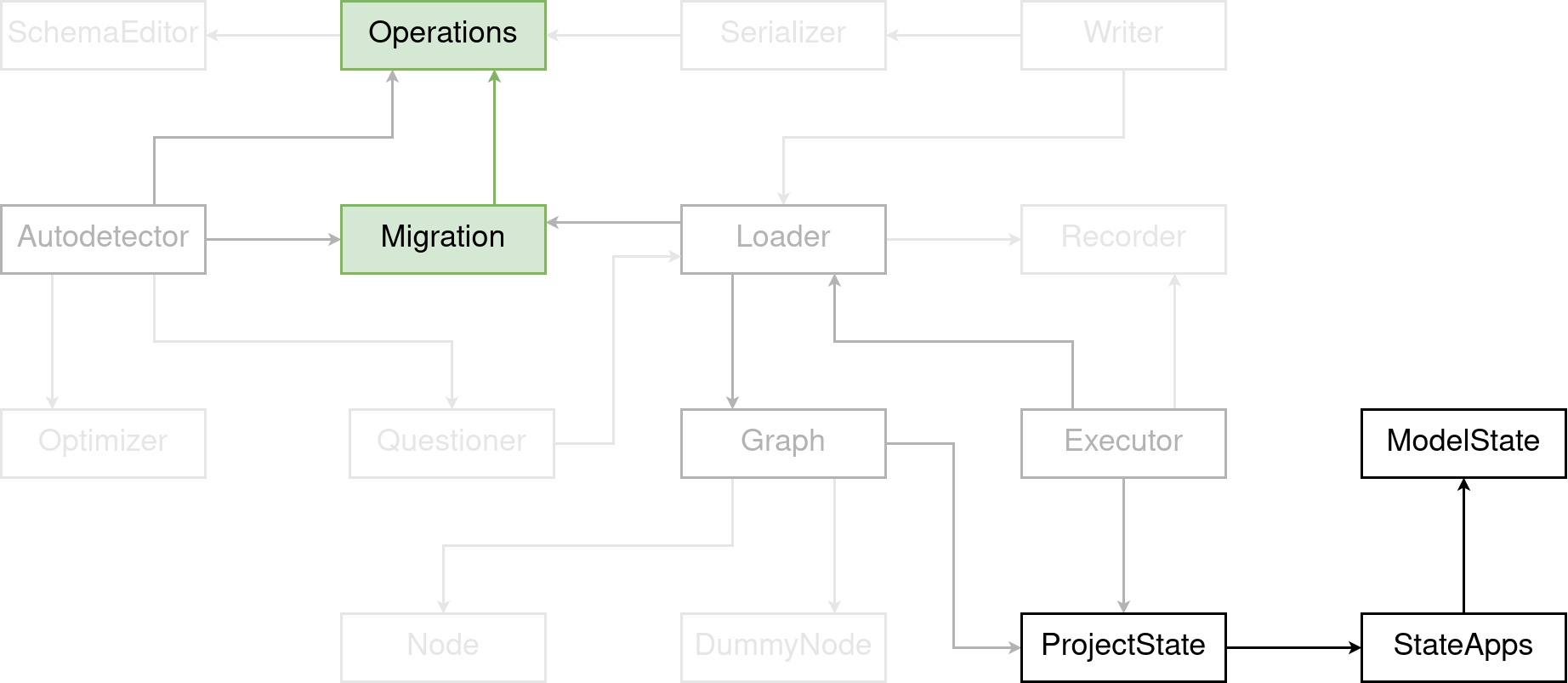
There are about two dozen migration operations. They are for example AddField and RemoveField, CreateModel and DeleteModel, but also less commonly used ones, like AlterOrderWithRespectTo, RemoveConstraint, or for example, PostgreSQL’s specific one, CreateExtension.
Operations have two tasks. They look at an instance of a ProjectState and then mutate the ModelStates that are in the ProjectState. It’s important to know that there’s only ever a “mutate forward”. The method on the Operation classes for that is called state_forwards().
The second thing operations do, is deciding on what to do with the database. For that, and unlike for the state, there are the database_forwards() and database_backwards() methods. They talk to the SchemaEditor and ask it for example to create a new table or add a column to an existing table.
A Migration is a bundle of these Operations. All Operations within a migration are executed in a single database transaction. That is, if the underlying database supports that.
A single migration is also always bound to a single Django app. Which means, all operations within the migration work on the same Django app. But, and I can’t stress that enough, each operation has access to the whole ProjectState, and thus to all apps and models. That is important when migrations deal with ForeignKeys. Because, let’s say, you change a model’s primary key from an Integer to a String. Then the AlterField operation will go through all models and check if there’s a field that points to the model you just change. And if there is, it will change that field’s database column’s data type as well.
Now that we know how the migration system keeps track of state and how to mutate the state and talk to the database, how does the framework know in which order the changes are applied?
Migration Graph
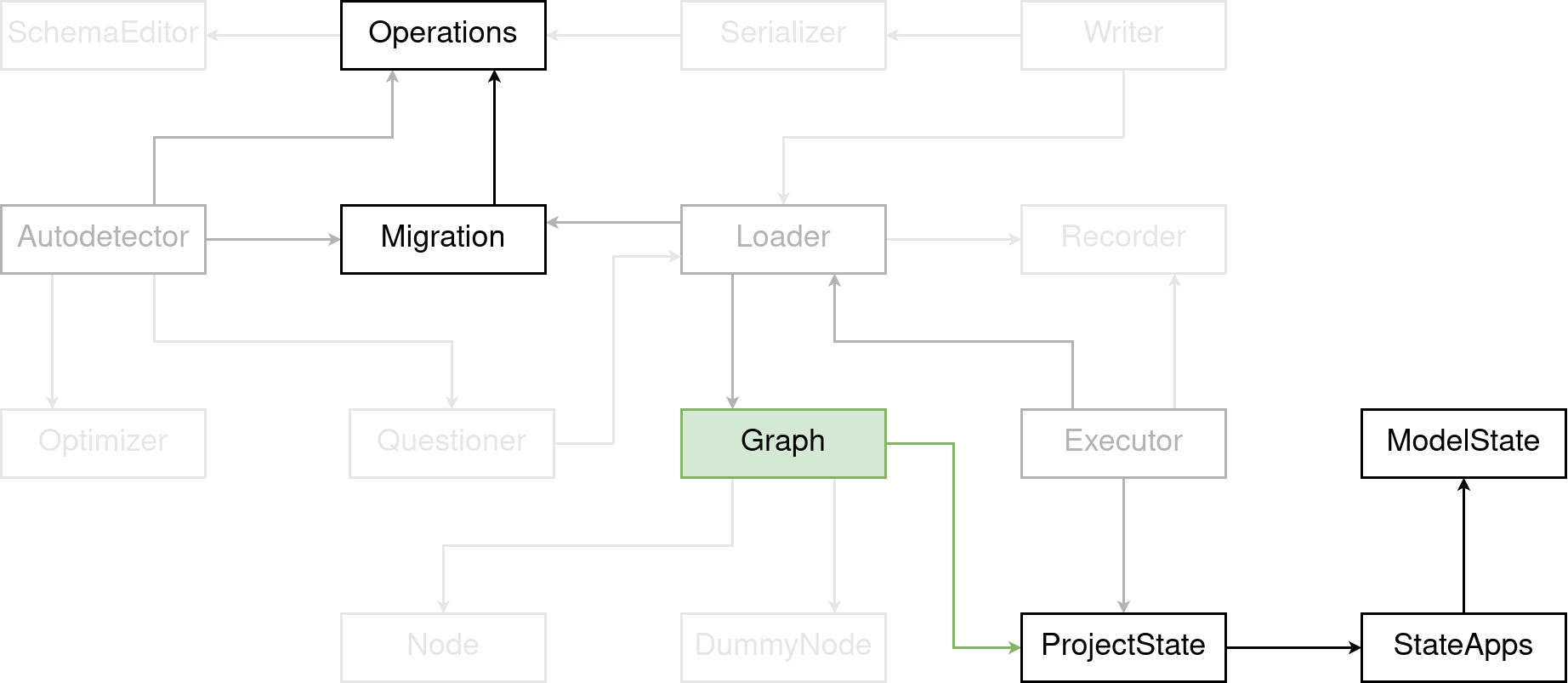
The answer to that is the MigrationGraph. And I’ll only briefly cover this one. In a mathematical sense, it’s a so-called directed acyclic graph.
A Migration has two, one might argue three, attributes that the graph considers for ordering:
First, and most commonly used: dependencies. That’s a list of other migrations that need to be applied before the migration in question can be applied. Let’s say, you have a migration that creates a model, and another migration that adds a ForeignKey on another model to that model. Well, The target model has to be created first. Otherwise the foreign key constraint can’t be fulfilled.
Second, barely known and less often used is the attribute run_before. It works exactly like dependencies. Just the other way around.
And third, there is the replaces attribute on a migration. Which comes into play when you squash migrations. And it essentially replaces a set of migrations with a single other one.
Now, the question arises, how does Django know about the migrations in your project? For that, there’s the migration loader
Migration Loader
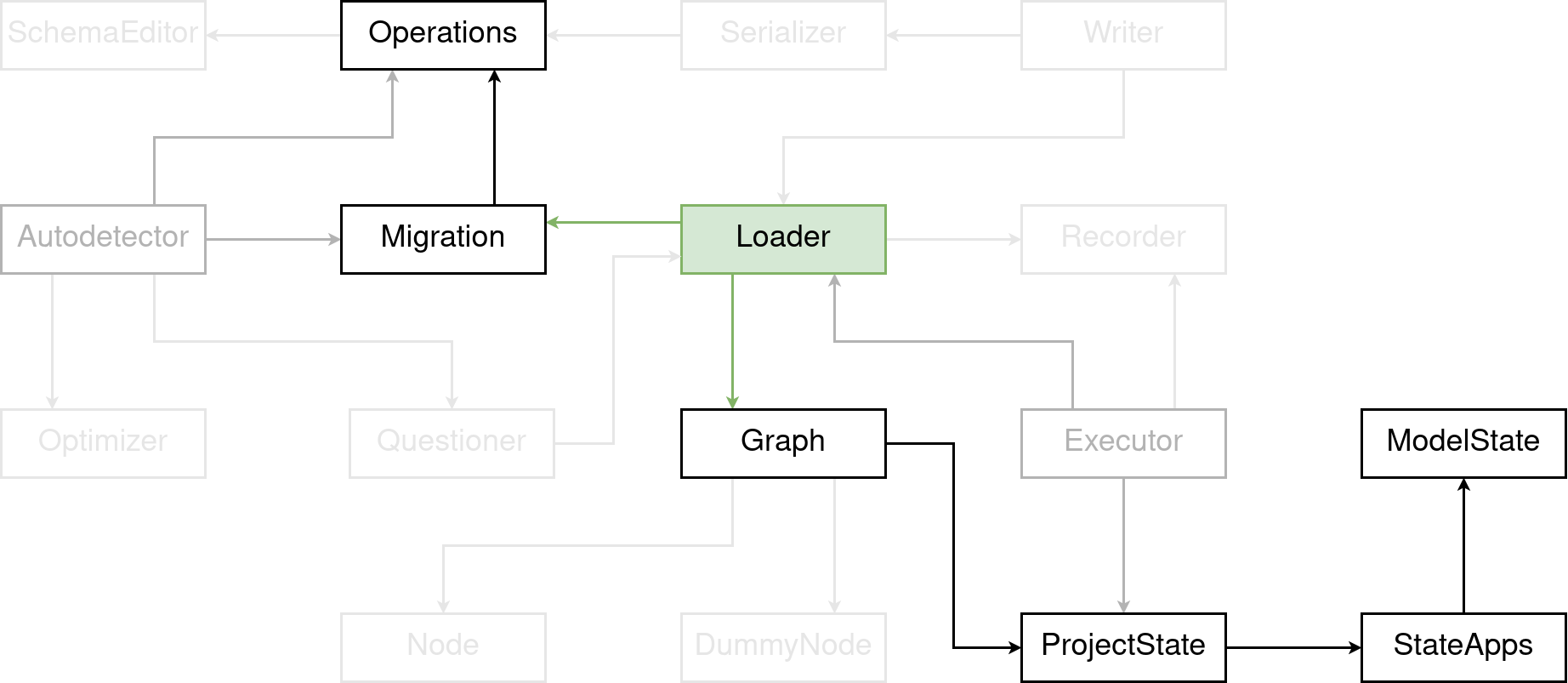
The potentially obvious task for the MigrationLoader, is loading all migration files from all apps in your Django project and adding them to the graph that we just talked about. As part of that, the loader is actually going to import the Python file that contains the migration and instantiate the Migration class with the app_label. This is where the migration gets the app_label from, since it’s not an attribute on the class.
But building the graph is easier said than done. Because, remember how I just quickly skipped over the replaces attribute on Migrations, and how it’s used with migration squashing? Well, building the _actual_ graph in the migration loader will need to account for that. The graph may go and replace some migrations with a replacement. But if some of the replaced migrations have already been applied, then the replacing one cannot be used. Instead, the remaining replaced migrations need to be used.
The loader does a few more things. For example, it checks that the migration history is sound. If you have applied migrations but some of its dependencies haven’t been applied. It’s going to yell at you.
And lastly, the loader provides an interface, to create a ProjectState from the underlying graph.
At this point, let’s recap what we have talked about so far. We know how to load migrations. We know how to turn them into a graph that defines in which order to do what. And we know the underlying data types that represent a database state at some time.
Which brings us to our next component.
Migration Executor
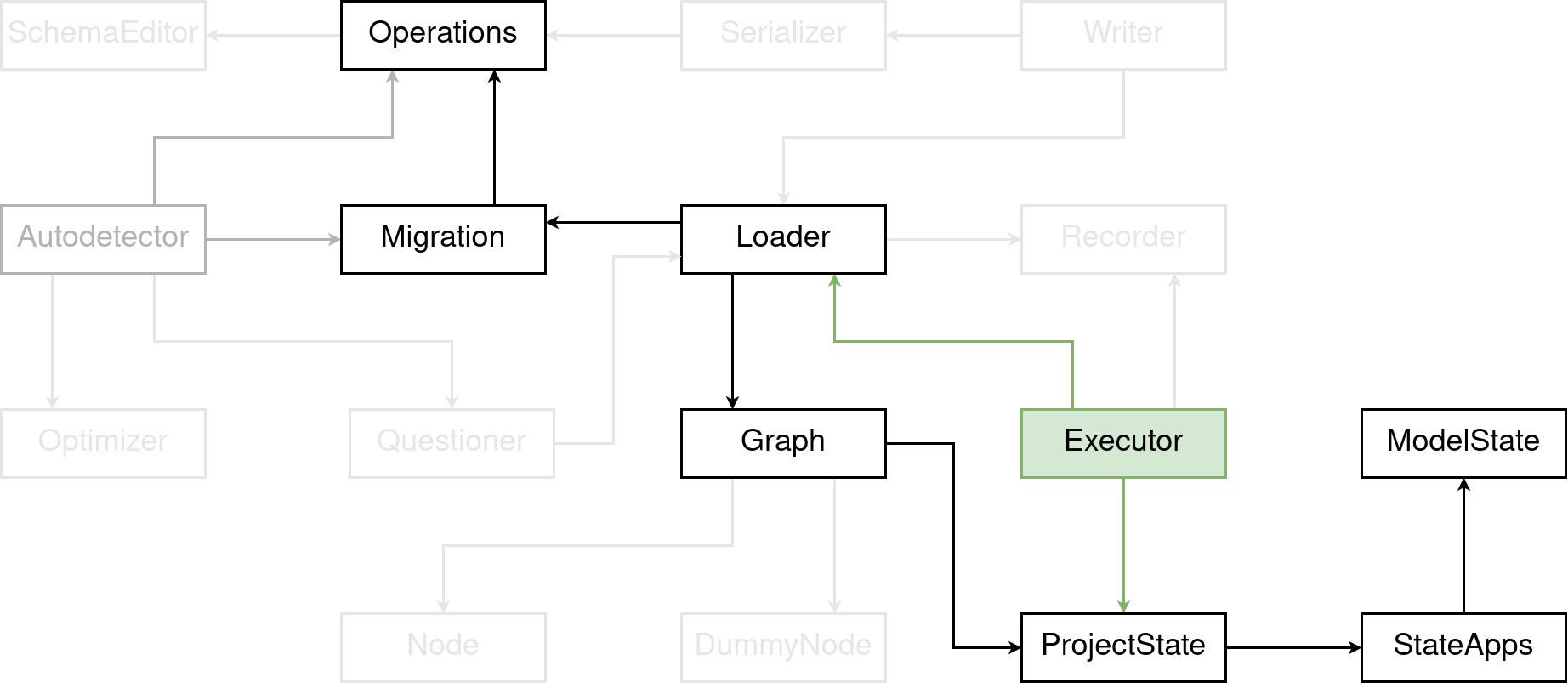
It’s the brain of applying and unapplying migrations. From the outside, there’s only one important method: migrate(). The method takes one required argument: targets. Targets are the names of the migrations that you want to have applied or unapplied at the end of the method call. Which means, if you want to apply your whole project, it is a list of all the last migrations in each app. These migrations are also called leafs.
From those targets, the executor will attempt to build a migration plan. If you’re curious, you can use the showmigrations management command with the --plan option to see what the plan would look like when you apply your whole project.
As part of building the plan, the executor will look at which migrations have already been applied and which ones are still outstanding. Or vice versa, the migrations that are applied and need to be unapplied.
Now, when migrating forward, that is, applying migrations, the executor is going to start with a fresh ProjectState and then iterates over all migrations in the plan and calls mutate_state() on each migration. Each migration will then in turn call state_forwards() on each migration operation. That builds up the representation of your database operation by operation. And it does that, up until the point when the first migration will need to be applied. Which means, up until the point when operations will need to talk to the database through the SchemaEditor.
At that point, the most crucial part of the migration process occurs: rendering models. After the rendering, the executor is going to call the apply() methods of each migration. Which will mutate the state forwards operation by operation, and also applies the database changes operation by operation.
Before I go into the unapplying part I want to demystify the “rendering of models”. Remember how, in the beginning I said that ModelStates are “just like a model”? And how a ProjectState knows about all ModelStates at a given time?
Model Field References

Model classes and their fields have references to each other and among each other. For example, you can use a model’s _meta API and get all fields on that model. And each field will have a model attribute, pointing back to that model.
And if you for example add a ForeignKey on model A, pointing to model B, then Django will automatically add a reverse ForeignKey, which is a ManyToOneRel, from B to A. Which is effectively a field on B. And the fields themselves will have the attributes related_model and remote_field which point to the corresponding part on the other side of the relation. So, adding a ForeignKey to A not only changes A but also B. And just with a few models and ForeignKeys you will end up with millions of pointers that the migration framework would need to keep track of.
Performance Considerations
To avoid that, the migrations work on ModelStates, which do not have these references. And because the SchemaEditor only works with model classes, the ModelStates need to be converted into them. And that’s called “model rendering”. And is a far better approach than working with model classes to start with. Because keeping track of these pointers is pretty much impossible. And you can trust me on that, because I’ve spend literal days debugging issues inside the migration framework where pointers where stale pointers were the cause of a problem.
There’s an infamous ticket #23745 which is about caching the rendered model classes. For those of you who’ve been around long enough, that is from Django 1.7 onwards, migrations got a significant speed boost in 1.8 with that ticket. There’s also a lot more into the rendering of ModelStates and ProjectStates that I’d love to write about but don’t have the time for. Like, for example, figuring out when to evict some cached model class. Which is enough content for a whole post.
Unapplying Migrations
Now for the unapplying part: It starts off like the applying part, by generating a plan to follow. But since ModelStates can only ever be mutated _forwards_, the executor will cache all intermediate ProjectStates for each migration that will be unapplied. If you’ve ever encountered a huge memory load during unapplying migrations, this is why. Once the ProjectStates have been cached, the executor is going to call a migration’s unapply() method. And it’s doing that in reverse order of the plan.
Migration Autodetector
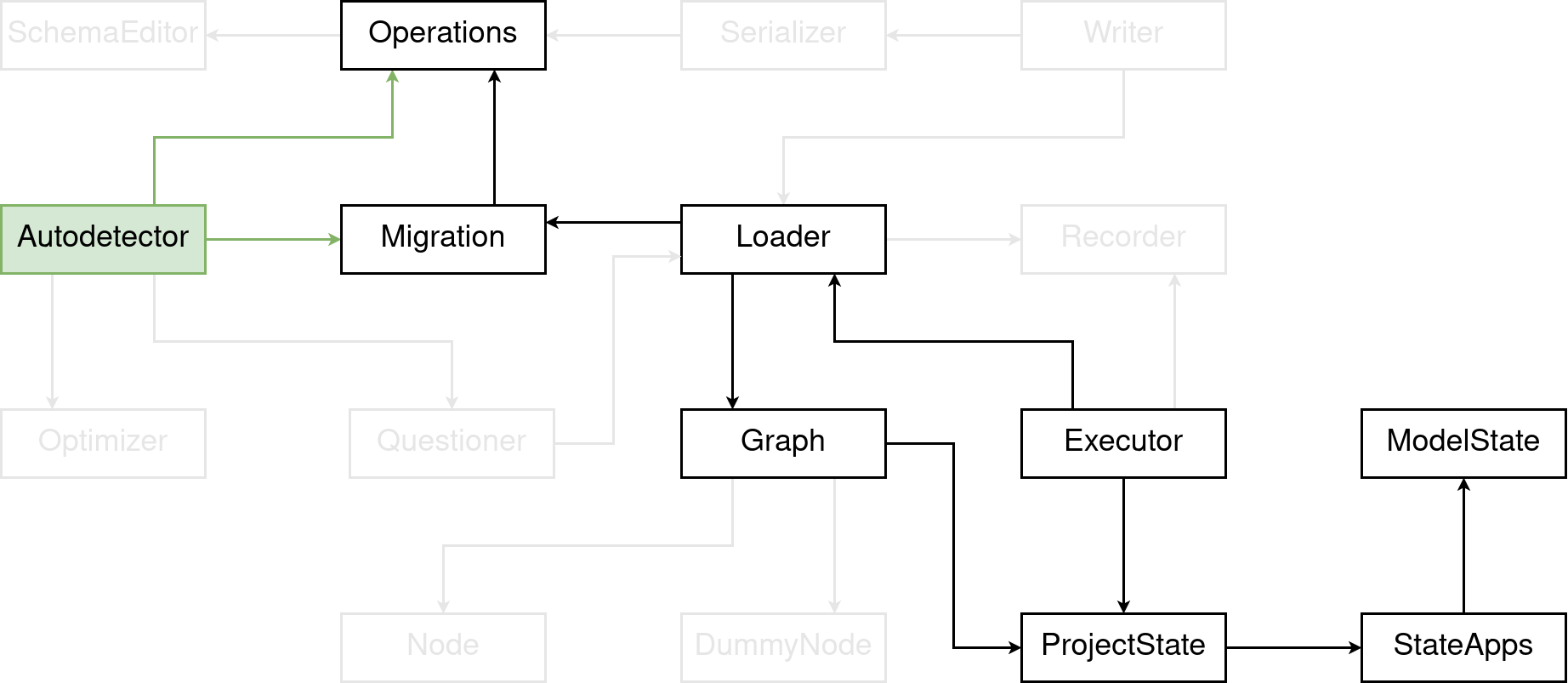
As the last trip of our journey through Django’s migration framework, I want to briefly look into the MigrationAutodetector.
The autodetector looks at your current models and the ProjectState represented by all migrations in your project, and then tries to figure out what operations need to be added in order to get your current ProjectState to the state that resembles the models in your project.
At this point, I was originally going to say “nothing is as simple as that”. Because, on the surface, it looks kind of simple. But the devil is in the details. There’s this method _detect_changes() which synchronously calls a dozen different methods to generate the changes needed for new and removed models, added and removed fields, and everything else one can do to a model. And each of the generation methods more or less works similar: they are iterating over all models in the ProjectState represented by migrations and the ProjectState``representing all models in your Django project. And for each model they then do their thing. For example, they compare the list of fields on a model and then decide that two fields were added and are not in your migrations yet. Thus, two ``AddField operations will be added. And it’s actually these generating functions that hide the complexity. And some of them are a few hundred lines long.
Summary
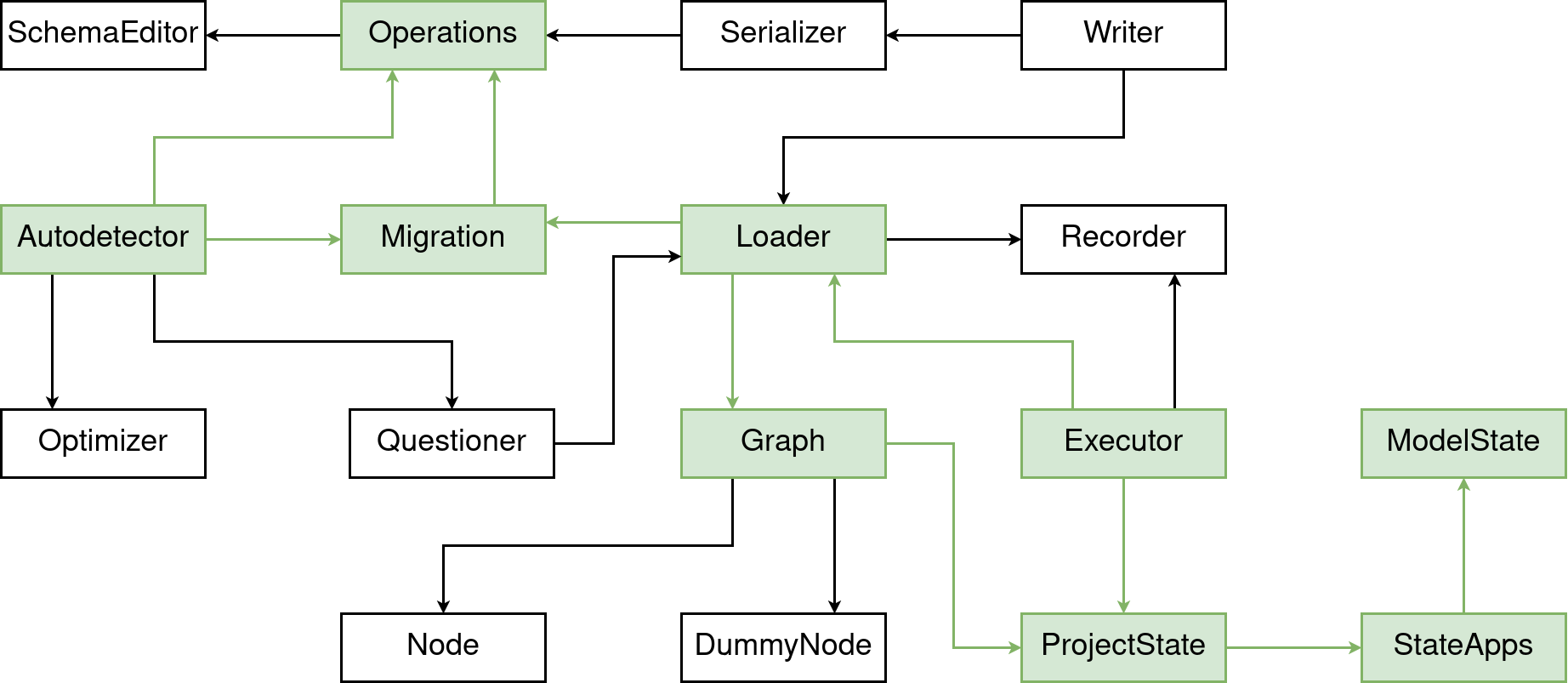
This concludes our journey through Django’s migration framework. As you’ve seen, there are numerous parts involved. And I can only encourage each and everyone of you to take a look at the code and explore it. And if you’ve been hesitant or scared away by its complexity so far, I hope this post made you curious to learn more.
FAQ
Why does changing verbose_name cause a migration?
A question that pops up repeatedly is around the field attributes. Such as, why does changing the verbose_name or choices cause a migration. With the post a hand, I hope you now know the answer now: because the ModelState for the corresponding model changes. And the reason why we can’t filter out some attributes is, that nobody knows which attribute somebody may or may not use inside some migration. Like, choices for example, it could be used to validate data in a data migration. Even though the attribute doesn’t have any effect on any database query in migrations.
Why can’t I remove old field classes?
Another question is about old field classes, and why they can’t be removed. And again, because of the ModelStates. If there’s only one migration in your Django project that refers to that field, well, the field class needs to stay around. You can use migration squashing to possibly get rid of the field. And if that doesn’t work automatically, maybe try writing the squashed migration by hand. But as long as there’s a single migration that still imports and uses the field, the field class needs to stay around.
Why doesn’t the SchemaEditor use ModelStates?
When I explained what “model rendering is”, one might ask, why does the SchemaEditor not “just work” with ModelStates. The answer to that is two fold.
Firstly, the SchemaEditor is part of the database backend and doesn’t “know” about the internals of the migration framework. Making it work with ModelStates would mean opening up some of the internal API, such as the ProjectState and ModelState. Which would not necessarily be an issue, because the benefits almost certainly outweigh the costs in this case.
Secondly, because that change needs to happen in a backwards compatible way. Which is where it gets fairly tricky. It’s not about the built-in database backends. The SchemaEditor has a publicly documented API. We will therefore need to provide a proper migration path covering one LTS cycle. Which adds a lot of maintenance burden. But there is ticket #29898 that is precisely about this: Adapting the SchemaEditor to operate on ModelStates instead of rendered models.