


To Index Or Not, That’s Not The Questions
Some Background Theory
As databases are used to store more and more information every day, these are also a key component in every Django project. Thus it’s important to understand how they work.
Of course I can’t explain all the details about all the different databases you can use with Django. Not only, because I don’t know all of that, but also because that would make for a hell of a talk. Or probably an entire conference.
The only thing about I want to say about the theoretical background on databases is, there’s something called “relational algebra”. With that every SELECT statement you could possibly come up with can be expressed. It’s mathematically proven.
How Database Lookups Work
Instead, let’s start with how lookups in databases work. Because that is what we do most the time.
Assume we have this database table of names of people and their corresponding age when they first started programming.
Now we want to select every persons that started at age 19.
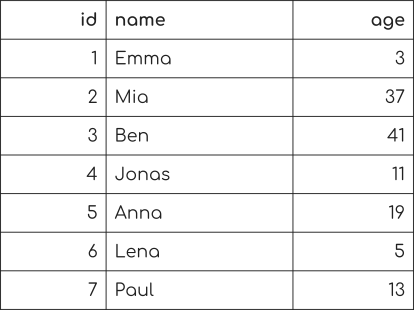
We can express that with a SQL query:
SELECT * FROM people WHERE age = 19
Now, how can we find each person matching that query?
Table Scan Lookup
Well, that’s fairly easy. We just look at each row in the table, check if the condition applies, and return the row if it does.
This is called a “Full Table Scan”
So far so good. We have 7 rows here. Thus we look at 7 rows. That’s a small number of rows, so the query is rather fast.
But imagine you have like 100 thousand, 100 million, 100 billion or even more rows. Iterating over every single row can be time consuming. And that’s not something we want or something we can afford. We want something that provides guaranteed timing to find a particular row. Independent of the number of rows.
This is where indexes join the party.
What Are Indexes?
Indexes give fast access to a single (or multiple) items without much speed reduction for an increasing amount of data. This is also called “Random Access”. You will see in a bit why it’s called that way. But first let us look into the most common index types in modern database systems.
B-Trees / B+ Trees
The most common indexes these days are B-Tree indexes. Or more precisely, B+ Tree indexes.
They are either named after one of their inventors, Rudolf Bayer, or because they are self-balancing. That’s not really clear but also doesn’t really matter. Self-balancing means that the trees have certain timing guarantees: the most interesting for B-Trees it doesn’t matter how big the index is, for any index of the same size the timing is going to be the same. You’ll see that in a bit as well.
As with every tree (both in Computer Science and in nature) you start with a root. The difference between Computer Science and Nature is, in Computer Science we put the root of a tree at the top.
Whatever. Here’s the root note of a B+ Tree of grade 3.
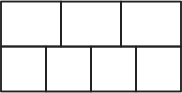
Grade 3 means, this node can have 3 keys. That’s what the 3 boxes at the top of that node are for. The 4 boxes underneath hold pointers to another node or a row in the database table.
Now, let’s say you have the keys 11 and 37 in this node and you don’t have a 3rd key.
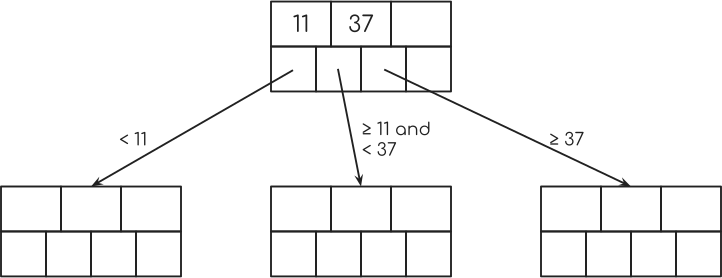
Then the leftmost pointer would point to a node with keys smaller than 11. The second pointer would point to a node with keys greater or equal than 11 and smaller than 37. The third pointer would point to a node with keys greater or equal than 37.
Having an index on the age column from the table I showed in the beginning, this could then look like this.
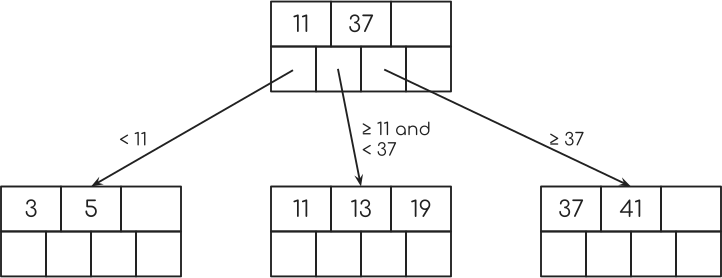
The magic now is what happens with the pointers in this second row of nodes. Each of them points to a single row in the table that has the particular key, which is the age in our example.
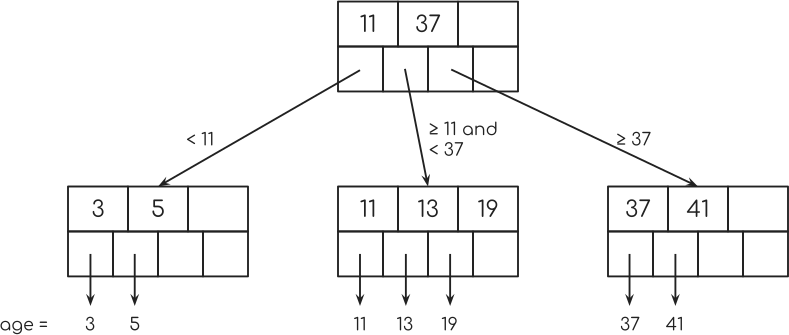
But it’s not just this.
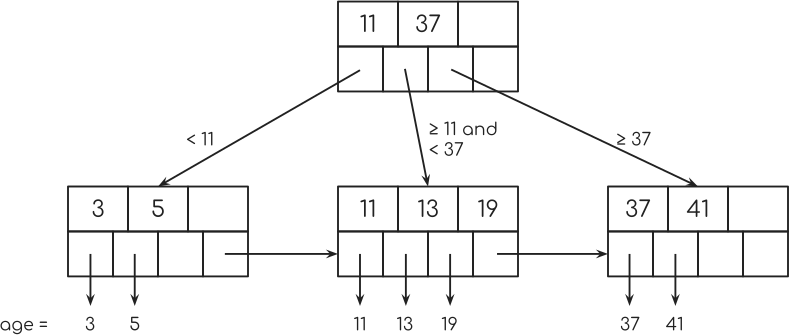
You see how the last pointer in each of the bottom nodes points to the next node? This is used for something called “Index Scan”. I’ll come back to that later.
Let’s look at the second row of nodes in a bit more detail.
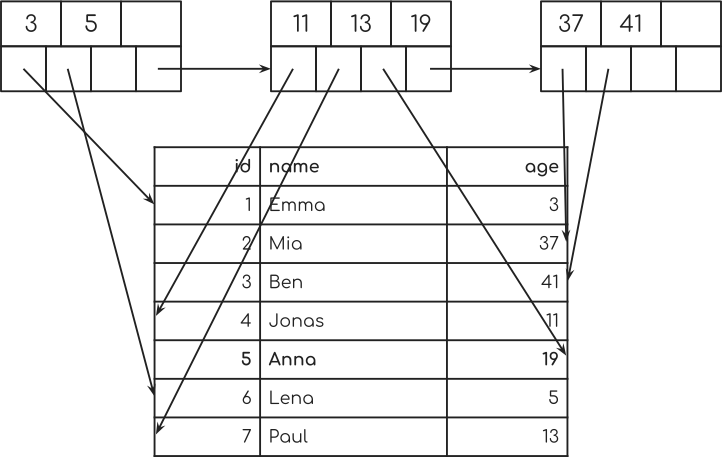
You can now see, how every pointer from one of those tree nodes points to a single row in the table.
You can also see how these pointers from the tree nodes somewhat randomly point to some rows in the table. That’s why this is called “Random Access”. The database randomly jumps around in the database table.
Random Access Lookup
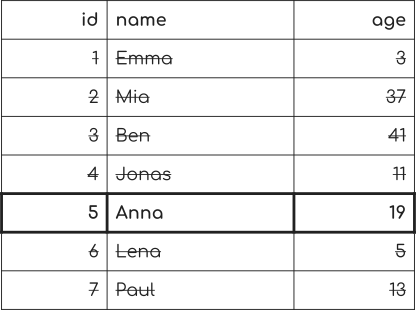
Let’s refresh our memory with the SQL query we had before.
SELECT * FROM people WHERE age = 19
How does an index now help to find the corresponding row faster?
Well, let’s look at the tree:
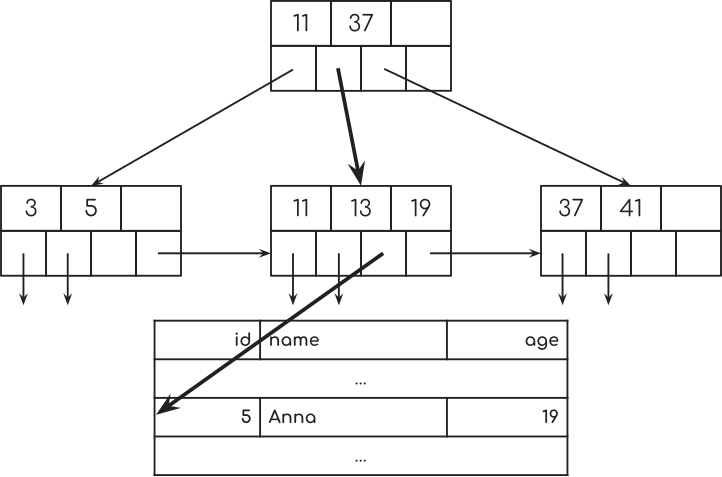
It requires 1 step to get from the first node to the second node. And a seconds step from the second node to the row in the database table.
Remember, we had to look through all 7 rows before to see if they matched the database query.
And since there’s no more key in the index with 19, we’re done.
Index Scan
Now, coming back “Index Scan”, assume you want to count the amount of people that started coding when they were in the age range from 5 to 13.
SELECT COUNT(*) FROM people WHERE age BETWEEN 5 AND 19;
SELECT COUNT(*) FROM people WHERE age >= 5 AND age <= 19;
The database will look for the key 5 and will then use the pointer to the next node to look for further keys.
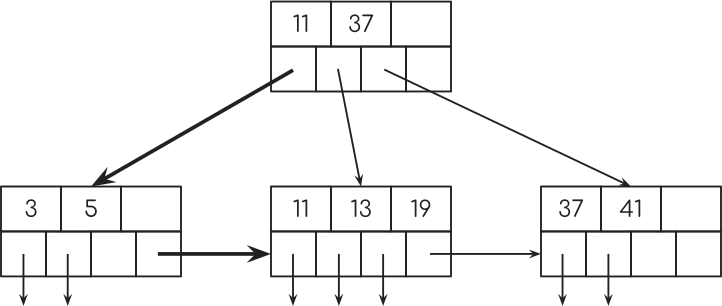
And because all the information that the database needs for the query is right here in the index, the database will not look at the table at all.
Indexes Are Awesome
Let’s have them in Django.
And we already do, actually.
There is
- db_index=True which you can set on a model field
- index_together=(('name', 'age'),) which you can set in a model’s Meta class
- ForeignKey() / OneToOneField() which use indexes for quick lookups of the data in related tables
- primary_key=True which Django automatically uses on the AutoField which represents the id column on every model.
This is already great. But this feature set is somewhat limiting. There are not just B+ Tree indexes out there. There are a ton more
2016
Let’s look at 2016.
Marc Tamlyn and I had ideas for indexes. Actually, Marc had some ideas during his contrib.postgres work already. And we had thoughts about APIs. And things we’d like to have in Django. Like, let’s make Django support all the indexes.
But we didn’t have time to implement our ideas!
But we got lucky. Actually, the Django Project got lucky.
Google Summer of Code 2016
Django was, once again, accepted as an organization for Google Summer Of Code. Thank you Google!
For those of you who don’t know what that is: Google pays a Student for 3 months to work on an Open Source project while being mentored by the project’s contributors.
For the most part Tim Graham, but also Marc and I mentored a student Akshesh Doshi tackling a more generic Index support in Django. From writing down a proposal for the API etc. until eventually merging things into Django.
The major outcome of GSoC 2016 is django.db.models.indexes.Index(fields, name) (docs)
It defines the base class of all indexes. You can use them via the indexes option in a model’s Meta class.
For example like this:
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=200)
class Meta:
indexes = [
models.Index(
fields=['name'],
name='name_idx',
),
]
This will create a B+ Tree index on the name column of the database table.
Granted, that’s nothing new. That’s what you can do with db_index=True on the name field.
You can of course also define an Index on multiple columns:
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=200)
age = models.PositiveSmallIntegerField()
class Meta:
indexes = [
models.Index(
fields=['name', 'age'],
name='name_age_idx',
),
]
Granted, that’s nothing new either. You can do with index_together already.
But you can now also do this:
from django.contrib.postgres.fields import JSONField
from django.contrib.postgres.indexes import GinIndex
from django.db import models
class Doc(models.Model):
data = JSONField()
class Meta:
indexes = [
GinIndex(
fields=['data'],
name='data_gin',
),
]
Define a GinIndex. That’s something PostgreSQL specific. But it’s something you could not do before. At least not reliably without too much pain.
A GinIndex can be used to index the key values inside a JSON blob. So you could filter for rows in a table where the key in a JSONB field maps to a particular value. That’s like the “NoSQL 1-0-1”.
Another built-in index type that ships with Django 1.11 is BrinIndex which, simply put, can allow for much faster computation of aggregations. Such as, finding the last time each article was purchased.
And because Indexes are parts of the database schema, they are obviously tracked through migrations. Thus the index is created when you run python manage.py migrate:
BEGIN;
--
-- Create model Doc
--
CREATE TABLE "someapp_doc" (
"id" serial NOT NULL PRIMARY KEY,
"data" jsonb NOT NULL);
--
-- Create index data_gin on field(s) data of model doc
--
CREATE INDEX "data_gin" ON "someapp_doc" USING gin ("data");
COMMIT;
Feature ideas
Great.
That’s what is in Django 1.11 which was released yesterday.
But what’s out there to come for Django 2.0?
What’s on the horizon?
What do we want to have eventually?
Functional Indexes
They are useful in all kinds of situations where you don’t want to index on the raw value but e.g. on a variation of it, such as lower-case of a string. I’m already working on that. I’m not quite there yet. I’d love some help from people understanding the expressions API.
from django.db import models
class Author(models.Model):
name = models.CharField(max_length=200)
class Meta:
indexes = [
FuncIndex(
expression=Lower('name'),
name='name_lower_idx',
),
]
db_index=<IndexClass>
Using indexes for a single column can be cumbersome as you’ve seen before. Thus, let’s support Index classes as an attribute to db_index.
from django.db import models
class Author(models.Model):
name = models.CharField(
max_length=200,
db_index=HashIndex
)
Field.default_index_class
Having a B+ Tree for some fields doesn’t make sense. As previously shown, there is a GinIndex that’s perfect for JSONField. Why not have a default_index_class per field class that’s being used when db_index=True?
from django.contrib.postgres.fields import JSONField
from django.contrib.postgres.indexes import GinIndex
from django.db import models
# Somewhere in Django’s JSONField implementation:
# JSONField.default_index_class = GinIndex
class Document(models.Model):
data = JSONField(db_index=True)
Refactor index_together and db_index
This one is more under the hood than user facing:
It would probably make sense for db_index and index_together to use Model._meta.indexes internally, I could imagine. That’s something to investigate.
GiSTIndex
There’s a GiSTIndex in PostgreSQL that can be used for geo-spacial queries, such as “give me all points that have a maximum distance of 10 to a given point”. It’s not in Django 1.11. I don’t know why, but I guess because nobody added it.
Sprints
And speaking about all these features, there are Sprints on Thursday and Friday. I hope you are staying and join us.
Talk to me or anybody else on the core team or any other attendee if you want to work on any of those tickets. Some of those ideas still need tickets in our issue tracker. And some also probably need some discussion on the django-developers mailing list. Now is the time to get these discussions starting if you want to have any of this in Django 2.0.
On that note, keep in mind that Django 2.0 will not support Python 2 anymore!