[CloudRAID] 4. Implementation
This post is a continuation of the blog series about the student research paper CloudRAID.
After Florian’s publications about the architecture the concrete implementation design will follow.
4. Implementation
4.1. JNI API
The supplied RAID 5 implementation uses SHA-256 for integrity and validity checks. The hash implementation has been taken from the Apache Portable Runtime Project (APR) that has been published by the Apache Software Foundation under the terms of the Apache License version 2.0.
4.1.1. Pre-compiler Flags and Constants
The native RAID 5 level implementation uses multiple pre-compiler flags and constants to control the split and merge processes:
- RAID5BLOCKSIZE specifies how many bytes the library will write at once to each device file (default 1024 bytes). Hence RAID5BLOCKSIZE × 2 bytes are read at once from the input file.
- Normally all data will be encrypted before it is being split into the device files. This can be changed by setting ENCRYPT_DATA to 0.
- The constant ENCRYPTION_SALT_BYTES specifies the size of the salt in bytes. The default value is 256.
- For debugging purposes, the DEBUG constant can be set. There are three debug levels possible, where 1 prints minimum debug information and 3 all. A value of 0 disables entirely disables the debug output.
- _NAME_, _VENDOR_ and _VERSION_ contain meta data for this library as exemplarily shown in listing 1. They information will be used by the native functions getName(), getVendor() and getVersion() as explained in chapter 4.1.3 - Function Signatures.
#define RAID5BLOCKSIZE 1024
#define ENCRYPT_DATA 1
#define ENCRYPTION_SALT_BYTES 256
#define DEBUG 0
#define _NAME_ "CloudRAID-RAID5"
#define _VENDOR_ "CloudRAID Team"
#define _VERSION_ "1.0.0-beta.1"
Listing 1: Pre-compiler flags and constants
4.1.2. Structs
For internal storage purposes, the native RAID implementation needs two C structs that are shown in listing 2:
- Lines 1 to 6 show the SHA-256 context that allows to iteratively calculate the hash sum of data larger than an internal boundary size by storing the algorithms state, among other things, within this struct. This struct’s usage, as well as how the Secure Hash Algorithm works, is not explained as part of this research paper.
- Lines 7 to 15 represent the information stored in a meta data file:
- First of all, each meta data file will contain a version number. This allows CloudRAID to implement backwards compatibility and makes the handling of new features to the native RAID implementation much more flexible.
- The unsigned char arrays hash_dev0, hash_dev1 and hash_dev2 are used to store the SHA-256 sum of the regarding device files, while hash_in stores the hash sum of the original input file. This makes it possible to verify the integrity of the output file. If any device file has been compromised, include the corresponding hash sum, the integrity check of the output file will fail.
- The salt is used to randomize the encryption key and hence increases the encryption strength.
- Finally the missing element contains information about how many bytes are missing on the secondary device (not the parity device) to fill the complete block. This is necessary due to the way CloudRAID handles files of a size different to the internal RAID5 block size.
struct sha256_ctx {
uint32_t state[8];
uint32_t total[2];
size_t buflen;
uint32_t buffer[32];
};
typedef struct raid5md {
unsigned char version;
unsigned char hash_dev0[65];
unsigned char hash_dev1[65];
unsigned char hash_dev2[65];
unsigned char hash_in[65];
unsigned char salt[ENCRYPTION_SALT_BYTES];
unsigned int missing;
} raid5md;
Listing 2: Structs used for internal storage within RAID level 5 imlementation
4.1.3 Function Signatures
The The Java Native Interface (JNI) implements six functions whereof two are directly used for the RAID features and three are used to determine some version and vendor information about the library. The remaining, sixth, function is used to exchange information about the size of the struct raid5md from the library to CloudRAID. The function signatures are shown in listing 3 and will be explained here. All JNI functions take at least two parameters: JNIEnv *env and jclass cls. The former parameter refers to the Java environment that provides functions to for example convert and access strings. The latter is the instance of the current object the JNI function is working in but is not used within the CloudRAID implementation.
- mergeInterface() in lines 1 to 4 is the function that is called to merge three device files to the output file. It takes the directory where the device files are stored as first (additional) argument. The file’s hash value is taken as second argument. The function will append the file extensions .0, .1, .2 and .m automatically. The third parameter defines the full path to the output file. The target directory must exist, otherwise an error will be returned while trying to open the output file. The last parameter is the secret part of the key that has been used during encryption. One must keep in mind, that the _tempInputDirPath must contain a trailing folder separator. On Unix systems, this is most likely the forward slash (/) and on Microsoft Windows the backward slash (\).
- splitInterface(), as defined in lines 5 to 8, is the function signature for split calls. The function takes four additional parameters: the first one specifies the base input directory for the file that will be split. The second parameter is the path, relative to the first parameter, that directs to the file. In a multi user environment, adding the user name or any other user-unique identifier to this relative path will ensure that every output file exists only once (as long as there are no hash collision for two files with different user identifiers). The file names for the output files will be the SHA-256 sum over the concatenation of _inputBasePath and _inputFilePath appended by .0, .1 and .2 for the device files and .m for the meta data file. The third parameter denotes the output directory. Finally, _key takes the secure part of the encryption key. In the same manner as in the mergeInterface() function, the paths _inputBasePath and _tempOutputDirPath must be terminated by folder separators.
- The functions getName(), getVendor() and getVersion() as defined in lines 9 to 14 do not take additional parameters. They can be used to show versioning information of this library that will then exemplarily be shown on the REST API information page (c.f. chapter 4.2.2 - Version Information).
- Lines 15 and 16 show the getMetadataByteLength() function that is for CloudRAID core internal use only and must return the size of the meta data file in bytes.
JNIEXPORT jint JNICALL Java_de_dhbw_1mannheim_cloudraid_core_impl_jni_RaidAccessInterface_mergeInterface(JNIEnv *env, jclass cls,
jstring _tempInputDirPath, jstring _hash, jstring _outputFilePath,jstring _key);
JNIEXPORT jstring JNICALL Java_de_dhbw_1mannheim_cloudraid_core_impl_jni_RaidAccessInterface_splitInterface(JNIEnv *env, jclass cls,
jstring _inputBasePath, jstring _inputFilePath, jstring _tempOutputDirPath, jstring _key);
JNIEXPORT jstring JNICALL Java_de_dhbw_1mannheim_cloudraid_core_impl_jni_RaidAccessInterface_getName(JNIEnv *env, jclass cls);
JNIEXPORT jstring JNICALL Java_de_dhbw_1mannheim_cloudraid_core_impl_jni_RaidAccessInterface_getVendor(JNIEnv *env, jclass cls);
JNIEXPORT jstring JNICALL Java_de_dhbw_1mannheim_cloudraid_core_impl_jni_RaidAccessInterface_getVersion(JNIEnv *env, jclass cls);
JNIEXPORT jint JNICALL Java_de_dhbw_1mannheim_cloudraid_core_impl_jni_RaidAccessInterface_getMetadataByteLength(JNIEnv *env, jclass cls);
Listing 3: JNI header functions signatures.
The main internal functions used by the primary two JNI functions above are explained in this paragraph. For both processes, split and merge, there are two functions each, split_file() and split_byte_block() (merge_file() and merge_byte_block() respectively) that actually handle the processes (see listing 4 at the end of this post). The JNI functions for split and merge must be seen as wrapper for the split_file() and merge_file() functions. These functions handle the complete processes show by the figures 1 and 2 (introduced and explained in a previous article of this article series). All FILE* parameters must be correctly opened for read or write access. On Unix systems this includes the binary b mode for fopen().
split_file() expects a file pointer (rb mode) to the input file as first parameter. The FILE *devices[] array must contain three elements to files opened in wb mode. These files are the device files. The meta parameter points to the meta data file as must have been opened in wb mode as well. const char *key is the secure key used for file encryption and will be passed to the hmac() function together with its length keylen.
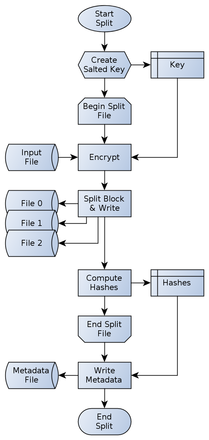
Figure 15: The nativ split process
This function reads up to 2 × RAID5BLOCKSIZE for each iteration shown in figure 1. These bytes are encrypted with the key generated by hmac() if ENCRYPT_DATA is not 0 and then passed to split_byte_block(). The call-by-reference “return” values are written to the device files. After each iteration the parity position is incremented. Starting with device 2 as parity for the first block, the parity position will be 0 for the second block and 1 for the third block. The forth block will restart with position 2.
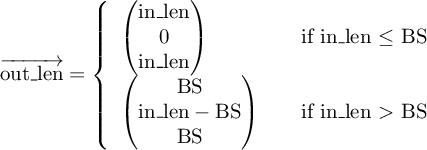
The split_byte_block() function takes the bytes read and encrypted in split_file() as first parameter and the length of that buffer as second parameter. The function splits the input character array in three parts that will be returned via the unsigned char *out parameter. The output size for each device is returned via the fourth parameter: size_t out_len[]. The alignment for the output buffer is as follows:
- The primary device content will be stored at out[0]. Its length is out_len[0].
- The secondary device content will be stored at out[RAID5BLOCKSIZE]. Its length is out_len[1].
- The tertiary device content, representing the parity device, will be stored at out[2 * RAID5BLOCKSIZE]. Its length is out_len[2].
Depending on the input length in_len the values of out_len[0] to out_len[2] may vary:
merge_file() is the inverse function to split_file(). It basically has the same function signature, but the first parameter specifies the output file unlike in split_file() and hence must be opened in wb mode. Thus the device files and meta data file, parameters two and three, are input files and therefore they must be opened in rb mode. The fourth parameter, const char *key is the secure key used for file decryption and will be passed to the hmac() function together with its length keylen in the same way as in split_file().
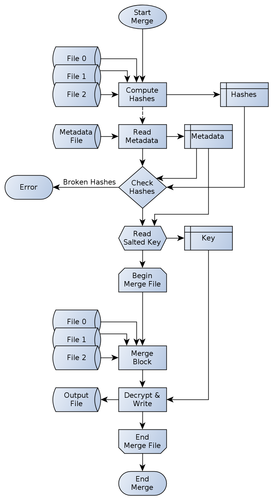
Figure 16: The native merge process
At first, the integrity of the device files is validated as shown in figure 2 by checking the hash sums for the device files. If more than two check sums are wrong the function terminates with an error. Otherwise the function will read up to RAID5BLOCKSIZE from each device file and passes those buffers with their respective lengths to merge_byte_block(). The call-by-reference “return” value from each block merge is passed to a SHA-256 context to validate the correctness of the output file and then decrypted.
The actual merge occurs in the merge_byte_block() function. Again the content for all three buffers is stored in a single character array as first parameter: const unsigned char *in. The second parameter, const size_t in_len[] represents the lengths for the three read buffers from the device files. Both parameters together align the input buffers in the same way as in split_byte_block():
- The primary device content will be stored at in[0].Its length is in_len[0].
- The secondary device content will be stored at in[RAID5BLOCKSIZE]. Its length is in_len[1].
- The tertiary device content, representing the parity device, will be stored at in[2 * RAID5BLOCKSIZE]. Its length is in_len[2].
The third parameter, parity_pos, specifies which device is the parity. This is necessary in combination with the fourth parameter, dead_device, to determine the merge strategy: concatenating the content of the buffers for device files 0 and 1 or using the parity in combination with either of first two device files. missing defines how many bytes are missing on the secondary device. Only the last block of each overall merge process may set this parameter to a value > 0. The penultimate parameter, *out stores the merged data with a total length of *out_len but at most 2 × RAID5BLOCKSIZE.
create_salt(): the complete security of the whole encryption process relies on the strength of the key given to split_file() and merge_file(). However, to protect the data against attacks using rainbow tables the encryption key is being salted. The salt of length ENCRYPTION_SALT_BYTES is generated by this function. On Microsoft Windows each byte of the salt will be set by a return value of rand() after initializing the pseudo random generator with srand(time(NULL)). On all other Operating Systems (OSs), that can be expect to be Unix, the functions reads ENCRYPTION_SALT_BYTES from /dev/urandom which can be seen to be random.
The salted key used during encryption and decryption is created by the function hmac(). This function is an implementation of the Federal Information Processing Standards Publication (FIPS PUB) 198 [NIS02] HMAC specification and takes five parameters: the first two parameters (*key and keylen) define the secure key given by the JNI function split_file() and merge_file(). Parameters three and four link to the *salt (optimally generated by the create_salt() function) and its length that is ENCRYPTION_SALT_BYTES by default. The last parameter, *hash, is a call-by-reference parameter and “returns” the HMAC for the given *key and *salt.
The general mode of operation can be expressed by the following two expressions:

The implementation of the HMAC [NIS02] standard has been validated by computing the digest values for the test cases 1, 2, 3, 4, 6 and 7 defined in RFC 4231 [Nys05]. Test case 5 has not been tested since the truncation is not needed in CloudRAID and was therefore not implemented.
int split_file(FILE *in, FILE *devices[], FILE *meta,
const char *key, const int keylen);
void split_byte_block(const unsigned char *in, const size_t in_len,
unsigned char *out, size_t out_len[]);
int merge_file(FILE *out, FILE *devices[], FILE *meta,
const char *key, const int keylen);
void merge_byte_block(const unsigned char *in, const size_t in_len[],
const unsigned int parity_pos, const unsigned int dead_device,
const unsigned int missing, unsigned char *out, size_t *out_len);
int create_salt(unsigned char *salt);
unsigned long hmac(const unsigned char *key,
const unsigned int keylen, const unsigned char *salt,
const unsigned int saltlen, unsigned char *hash);
Listing 4: Internal native header function signatures
Sources
| [NIS02] | NIST Computer Security Division (CSD). The Keyed-Hash Message Authentication Code (HMAC). Federal Information Processing Standards Publication FIPS PUB 198, National Institute of Standards and Technology, March 6, 2002. http://csrc.nist.gov/publications/fips/fips198/fips-198a.pdf. |
| [Nys05] | Magnus Nystrom. Identifiers and Test Vectors for HMAC-SHA-224, HMAC-SHA-256, HMAC-SHA-384, and HMAC-SHA-512, December 2005. http://tools.ietf.org/html/rfc4231 |